10.1 깊이 버퍼를 이용한 삼각형 래스터화의 기초
시각적인 사실성을 희생해서라도 실시간 성능을 얻고자 하는 방식부터 포토리얼리즘을 위해서 실시간 동작을 포기하는 방식까지 다양한 형태의 렌더링 기법이 존재한다.
10.1.1.1 고성능 렌더링 프로그램에서 쓰이는 형식
영화의 컴퓨터 그래픽에서는 표면을 주로 사각형 패치로 나타내는데, 패치는 적은 수의 컨트롤 포인트에 의해 정의되는 2차원 스플라인으로 구성된다. 사용되는 스플라인의 종류는 베지어 표면, NURBS, 베지어 삼각형, N-패치 등이 사용된다.
픽사의 렌더맨(RenderMan)같은 고급 영상용 렌더링 엔진은 기하 형상을 정의하는데 분할 표면을 사용한다. 모든 표면은 컨트롤 다각형으로 이루어진 메시로 표현하는데, 캣멀-클락(catmull-Clark) 알고리즘을 이용하면 다각형을 계속 더 작은 다각형으로 재분할 수 있는 특징이 있다. (거리에 따른 LOD 수준을 조정할 수 있다.)
10.1.1.2 삼각형 메시
삼각형을 실시간 렌더링에 사용하는 이유
ㄴ 표면을 만들 수 있는 가장 작은 단위의 다각형이기 때문 (단순함)
ㄴ 삼각형은 언제나 평평하다. (정점들이 한 평면에 존재함이 보장됨)
ㄴ 시중에 존재하는 거의 모든 그래픽 가속 하드웨어는 삼각형 래스터 변환으로 디자인되어 있다.
테셀레이션
표면을 여러 개의 분할된 다각형으로 쪼개는 과정이다. 게임에 쓰이는 삼각형 메시의 문제점 중 하나는 아티스트가 처음에 메시를 만들 때 얼마만큼 테셀레이션할 지가 고정된다는 점이다. 고정된 테셀레이션을 쓰면 물체의 윤곽이 거칠게 보일 수 있다.
기하 셰이더를 사용하여 LOD를 구현하는 방법
https://lemonyun.tistory.com/53
12. 기하 셰이더
기하 셰이더는 기본도형을 입력받는다. 기본도형 마다 기하 셰이더가 실행된다. 기하 셰이더는 기하구조를 새로 생성하거나 폐기할 수 있다. 기하 셰이더에서 나오는 정점 위치들은 반드시 동
lemonyun.tistory.com
GPU상의 동적 LOD를 덮개 셰이더에서 구현하는 방법
https://lemonyun.tistory.com/55?category=1020933
14. 테셀레이션 단계들
테셀레이션을 사용하는 이유 1. GPU상의 동적 LOD 2. 효율적인 물리 및 애니메이션 계산 ㄴ 물리와 애니메이션을 저다각형 메시에 대해 수행하고, 그 저다각형 메시를 테셀레이션해서 고다각형 버
lemonyun.tistory.com
10.1.1.3 삼각형 메시 만들기
감기 순서
ㄴ 감기 순서에 따라 전면 삼각형과 후면 삼각형을 구분하기 때문에 감기 순서를 혼동하지 않도록 주의해야 한다.
삼각형 리스트
ㄴ 메시를 이루는 각 삼각형의 정점을 3개씩 묶어 리스트로 나타내는 방식 (리스트의 크기는 삼각형 개수 * 3)
인덱스 삼각형 리스트
ㄴ 삼각형 리스트를 사용하면 중복되는 정점이 있을 수 있기 때문에 메모리가 낭비될 수 있다. 정점 버퍼와 인덱스 버퍼
스트립(strip)과 팬(fan)
ㄴ 인덱스 버퍼를 사용할 필요가 없으면서 정점의 중복을 줄여주는 효과가 있다.

정점 캐시 최적화
스트립과 팬을 쓰는 이유는 GPU가 비디오 RAM을 접근할 때 캐시 일관성을 향상시킬 수 있기 때문이다.
오프라인 기하 형상 처리 도구인 정점 캐시 최적화 도구를 사용하면 정점의 캐시 재사용성이 최대가 되도록 삼각형을 재배열해준다. 이는 인덱스 삼각형 리스트를 사용하더라도 캐시 최적화 효과를 얻을 수 있게 해준다.
10.1.1.4 모델 공간
삼각형 메시의 위치 벡터들을 나타낼 때는 대개 사용하기 편한 지역 좌표계 (local space) 를 기준으로 삼는다.
10.1.1.5 월드 공간과 메시 인스턴스
각각의 메시들은 월드 공간 (world space)이라고 불리는 공통 좌표계를 기준으로 자리를 잡고 방향을 정해 완전한 장면을 구성한다. 한 장면에서 메시 하나가 여러 번 등장할 수 있는데 이 같은 물체를 메시 인스턴스라고 부른다.
메시 인스턴스에는 공통 메시 데이터에 대한 참조, 로컬 공간에서 월드 공간으로 변환하는 행렬 (월드 행렬 : world matrix) 이 포함되어 있다.
메시를 월드 공간으로 변환할 때, 메시의 정점에만 월드 행렬을 곱하는 것이 아니라 법선 벡터에도 곱해줘야 한다. 월드 행렬에 스케일이나 전단 변환이 없는 경우에는 그냥 곱하면 된다.
10.1.2 표면의 시각적 속성
난반사 색상(diffuse color), 반사율, 질감, 투명도, 굴절 정도 같은 표면 속성을 정의할 수 있다.
포토리얼리즘을 추구하는 이미지를 렌더링할 때 가장 중요한 점은 물체에 반응하는 빛의 작용을 제대로 처리하는 것이다. 그렇기 때문에 렌더링 엔지니어는 빛의 원리와 전달 방식, 그리고 가상 카메라에서 빛을 감지하고 이것을 스크린의 색으로 변환하는 방식 등을 잘 알고 있어야 한다.
https://lemonyun.tistory.com/49
8. 조명
8.1 빛과 재질의 상호작용 조명을 사용할 때에는 정점 색상들을 직접 지정하지 않음. 표면의 재질들과 표면에 비출 빛들을 지정하고 조명 방정식을 적용해서 정점 색상이 결정되게 한다. 국소 모
lemonyun.tistory.com
10.1.2.1 빛과 색에 대한 기초
빛과 물체의 상호작용
ㄴ 흡수된다.
ㄴ 반사된다.
ㄴ 물체를 통과한다. (= 굴절되어 통과한다)
ㄴ 매우 가는 틈새를 통과할 때 회절된다.
포토리얼리즘을 추구하는 대부분의 렌더링 엔진은 앞의 세 가지 요소를 모두 고려한다. 회절은 대부분의 경우 눈에 드러나지 않아 구현하지 않는 경우가 많다.
10.1.2.2 정점 속성
일반적인 삼각형 메시는 다음의 속성들 중 일부 혹은 전부를 각 정점에 담고 있다.
ㄴ 위치 벡터
ㄴ 정점 법선
ㄴ 정점 탄젠트와 바이탄젠트 - 정점 법선과 각각 수직이며 서로 수직이어서 3개의 벡터는 탄젠트 공간의 좌표축을 나타낸다. 탄젠트 공간은 다양한 픽셀 단위 조명 계산에 이용되며, 여기에는 법선 매핑과 환경 매핑이 해당된다.
ㄴ 난반사 색
ㄴ 정반사 색
ㄴ 텍스처 좌표
ㄴ 스키닝 가중치
10.1.2.3 정점 형식
정점 속성을 저장할 때는 보통 C의 구조체나 C++ 클래스 등의 자료 구조를 사용한다. 이 같은 자료 구조의 레이아웃을 정점 형식(vertex format) 이라고 한다. 메시 종류마다 다른 속성을 조합해 쓰기 때문에 각기 다른 정점 형식이 필요하다.
// 1. 가장 단순한 정점 - 위치만 있다.
//
// z-프리패스, 카툰 렌더링의 실루엣 경계 검출, 그림자 볼륨 밀어내기 등에 유용하다.
//
struct Vertex1P
{
Vector3 m_p; // 위치
}
// 2. 흔히 쓰이는 정점 형식, 정점 법선과 텍스처 좌표 한 벌을 갖는다.
//
struct Vertex1P1NiUV
{
Vector3 m_p; // 위치
Vector3 m_n; // 정점 법선
F32 m_uv[2]; // (u, v) 텍스처 좌표
}
// 3. 스키닝에 쓰이는 정점, 위치, 난반사 색, 정반사 색 및 4개의 정점에 대한 가중치를 갖는다.
//
struct Vertex1P1D1S2UV4J
{
Vector3 m_p; // 위치
Color4 m_d; // 난반사 색과 투명도
Color4 m_s; // 정반사 색
F32 m_uv0[2]; // 첫 번째 텍스처 좌표
F32 m_uv1[2]; // 두 번째 텍스처 좌표
U8 m_k[4]; // 스키닝에 쓰이는 4개의 관절 인덱스
F32 m_w[3]; // 3개의 가중치 (마지막 가중치는 1 - 나머지 가중치의 합)
}DirectX 루나 책의 모든 예제에서는 하나의 메시가 하나의 머터리얼(난반사 색, 거칠기 계수, 매질의 반사율 속성)을 가지도록 설계되었기 때문에 정점 구조체에 굳이 머터리얼 속성을 넣지 않고 상수 버퍼를 통해 전달했다.
10.1.2.4 속성 보간
메시 표면 속성을 정점 단위가 아니라 픽셀 단위로 얻기 위해 정점 단위 속성 데이터를 선형 보간하여 픽셀 단위의 속성 데이터를 얻을 수 있다.
색상, 텍스처 좌표, 정점 법선과 같은 정점 속성 정보들을 보간할 수 있다.
10.1.2.5 텍스처
텍스처의 기본 단위는 텍셀이라고 부른다.
텍스처 종류
ㄴ 난반사 맵 (= 알베도 맵) : 메시의 벽지 역할을 한다. 텍셀에 표면의 난반사 색(벡터)를 담은 텍스처
ㄴ 법선 맵 : 텍셀의 단위 법선 벡터를 담은 텍스처
ㄴ 환경 맵 : 물체에 의해 반사된 주변의 환경을 물체에 입히기 위해 주변의 환경 이미지를 담은 텍스처
ㄴ 글로스 맵 : 각 텍셀이 얼마나 반짝이는지를 담은 텍스처
텍스처 좌표
ㄴ 2차원 좌표계 (u, v), 값의 범위는 (0, 0) ~ (1, 1)이다.
텍스처 주소 지정 방식
텍스처 좌표의 정의역 [0, 1] 바깥의 좌표가 주어졌을 때의 처리 방식
1. 순환 (wrap)
2. 테두리 색상 (border color)
3. 한정 (clamp)
4. 반사 (mirror)
텍스처 형식
요즘의 그래픽 카드와 그래픽 API들은 압축 텍스처를 지원한다.
DirectX는 DXT라고 알려진 압축 형식들을 지원한다.
압축 텍스처는 압축하지 않은 텍스처에 비해 메모리를 작게 사용하고 렌더링도 빠르다.(캐시 성능에 유리한 메모리 접근 패턴) 하지만 상황에 따라 텍스처가 이상하게 보이는 경우도 있으므로 잘 써야 한다.
밉맵과 필터링
https://lemonyun.tistory.com/50
9. 텍스처 적용
9.2 텍스처 좌표 법선 벡터와 마찬가지로 삼각형의 정점마다 텍스처 좌표를 지정해주면 보간에 의해 삼각형의 모든 점마다 그에 대응되는 텍스처 좌표가 결정된다. 9.3 텍스처 자료 원본 DDS (Direct
lemonyun.tistory.com
10.1.2.6 재질
재질 (Material)이란 메시의 시각적인 속성을 통틀어 일컫는 용어다. 메시 표면에 매핑되는 텍스처를 비롯한 하이레벨 속성들 (셰이더 프로그램, 셰이더에 들어갈 입력 인자들, 그래픽 가속 하드웨어를 제어하는데 쓰이는 인자) 이 포함된다.
3차원 모델은 일반적으로 여러 개의 재질을 사용한다. 이런 이유 때문에 메시 하나를 여러 개의 하부 메시로 나눠 각각 한 개의 재질에 연결하는 경우가 많다.
10.1.3 조명의 기본
10.1.3.1 지역 조명과 전역 조명 모델
빛 - 표면, 빛 - 공간 간의 상호작용에 관한 수학적 모델을 빛 수송 모델(Light Transport Model) 이라고 한다.
1. 지역 조명 모델
ㄴ 빛이 방출돼 물체 하나에만 반사된 후 바로 가상 카메라의 상 표면에 맺히는 직접 조명만 계산에 넣는 모델
2. 전역 조명 모델
ㄴ 간접 조명(빛이 여러 표면에 여러 번 반사해서 카메라에 도달하는 빛)을 고려하는 조명 모델
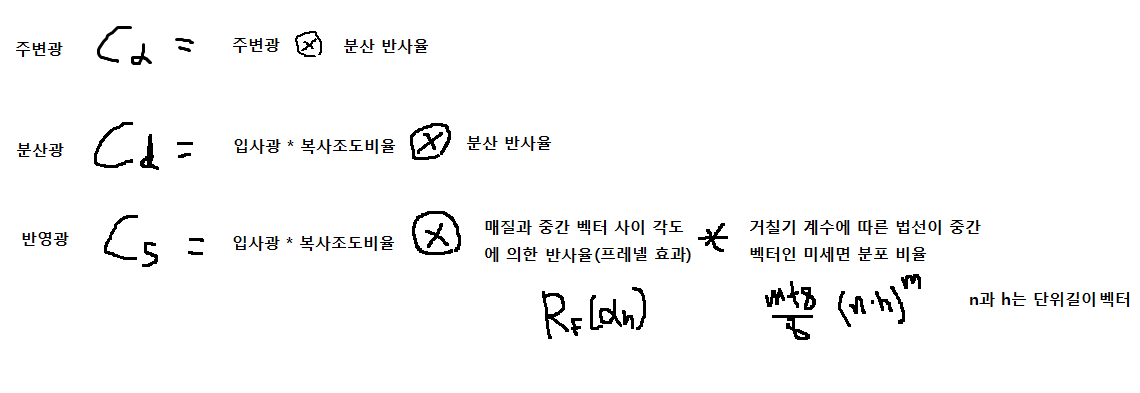
10.1.3.2 퐁 조명 모델
게임 렌더링 엔진들이 가장 흔히 사용하는 지역 조명 모델은 퐁(Phong) 반사 모델이다.
이 모델에서는 표면에서 반사되는 빛은 다음과 같은 세 가지 항의 합으로 표현된다.
ambient(환경, 주변)광 + diffuse(난반사, 분산)광 + sepcular(정반사, 반영)광
10.1.3.3 광원 모델링
정적 조명
ㄴ 미리 계산해 놓은 것을 그대로 쓰는 방식, 오프라인에 조명을 계산하는 것이 바람직함
ㄴ 조명 정보를 난반사 텍스처에 직접 입히는 방법은 좋지 않은 방법이다. 난반사 텍스처 맵은 장면의 다양한 곳에 반복적으로 사용되는 경우가 많기 때문이다.
ㄴ 광원마다 조명 맵을 생성하고 영향 범위 안에 들어오는 모든 물체에 이를 적용하는 방식을 쓴다.
환경광 광원 (주변광, Ambient Lights)
ㄴ 환경광 광원의 강도와 색은 월드 내 지역마다 다를 수 있다.
방향 광원 (Directional Lights)
ㄴ 태양에서 나오는 빛과 같이 무한히 먼 거리에서 오는 광원을 모델링한다.
ㄴ 빛의 색 C와 방향 벡터 L로 나타낸다.
점광 (Omni-Directional Lights)
ㄴ 분명한 위치가 있고 모든 방향으로 균등한 빛을 내는 광원을 모델링한다. 렌더링 엔진은 점 광원의 범위 안에 들어가는 표면에만 조명을 적용한다.
ㄴ 위치 P, 빛의 색 / 강도 C, 최대 범위 r로 나타낸다.
점적광 (Spot Lights)
ㄴ 빛의 안쪽 범위와 바깥 범위를 나타내는 원뿔 두 개를 사용한다.
ㄴ 위치 P, 안쪽 원뿔의 각도, 바깥 원뿔의 각도, 빛의 색 C, 중심 방향 벡터 L, 최대 반지름 r로 나타낸다.
면적 광원
ㄴ 직접 모델링하는 대신 그림자를 여러개 만든 후 블랜딩하거나 그림자의 날카로운 경계를 둔하게 만드는 방법도 있다.
발광체
ㄴ 표면 자체가 빛을 내는 광원인 경우
ㄴ 발광하는 표면은 발광 텍스처 맵(emissive texture map, 주변 환경이 어떻든 온전한 강도의 색을 가지는 텍스처)으로 모델링할 수 있다.
10.1.4 가상 카메라
10.1.4.1 뷰 공간
DirectX는 왼손 좌표계를 사용하기 때문에 다음과 같은 그림처럼 된다.
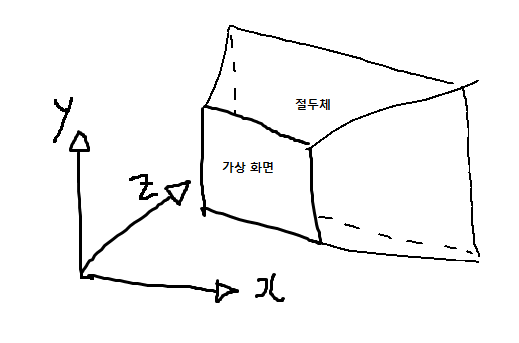
월드 공간의 정점을 뷰 공간의 정점으로 변환하는 행렬을 뷰 행렬이라고 부른다.
뷰 행렬은 카메라의 로컬 행렬의 역행렬이다.
메시 인스턴스를 렌더링하기 전에 월드 행렬과 뷰 행렬을 미리 결합해두는 경우가 많다.
이는 정점을 모델 공간에서 뷰 공간으로 변환할 때 행렬 곱셈을 한 번만 해도 되게 해준다.
10.1.4.2 투영
뷰 공간을 직교 투영, 원근 투영할 수 있다.
투영 행렬은 뷰 공간의 정점을 동차 클립 공간(homogeneous clip space)이라고 불리는 좌표계로 변환한다.
원근 투영은 길이가 보존되지 않는다. 실제 카메라가 찍는 것과 같이 멀리있는 물체는 작게 보인다.
직교 투영은 길이가 보존된다. 주로 3차원 모델 편집이나 게임 레벨 편집 시에 사용한다.
10.1.4.3 뷰 볼륨과 절두체
카메라가 볼 수 있는 영역을 뷰 볼륨이라고 한다. 뷰 볼륨은 평면 6개로 정의한다.
뷰 볼륨을 이루는 여섯 평면들은 원소가 4개인 벡터를 6개 써서 표현할 수 있다.
원근 투영을 사용해 장면을 렌더링하는 경우 뷰 볼륨은 절두체가 되고 직교 투영의 경우는 그냥 직육면체가 된다.
10.1.4.4 투영과 동차 클립 공간
동차 좌표계 벡터를 3차원 좌표계(정규화된 장치 좌표 공간 : NDC) 로 바꾸려면 x, y, z 성분을 w 성분으로 나눠야 한다. (원근 나누기)
동차 좌표의 w 성분은 뷰 공간 z좌표와 같다. (DirectX 기준)
원근 보정 정점 속성 보간
속성 보간은 스크린 공간에서 수행하는데, 장면을 원근 투영한 후 렌더링할 때는 원근 단축 효과를 감안해야 한다.
ㄴ 두 정점을 보간할 때 두 정점의 속성값을 각 정점의 z 좌표(깊이)로 나눠야 한다.
10.1.4.5 스크린 공간과 화면 비율
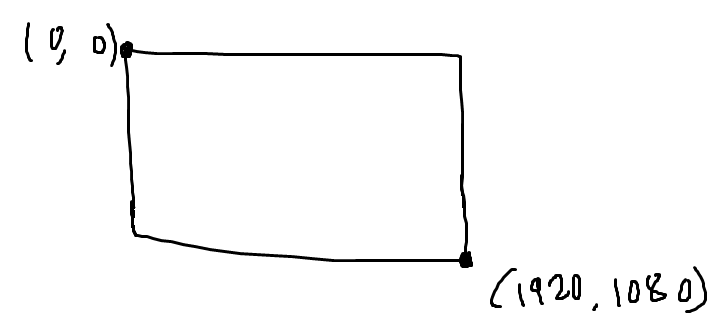
스크린 공간은 2차원 좌표계로, 좌표축 단위는 스크린 픽셀이다. 원점은 화면 왼쪽 위, x 축은 오른쪽 방향, y축은 아래 방향이다.
10.1.4.6 프레임 버퍼
렌더링한 최종 이미지는 프레임 버퍼라고 불리는 비트맵 컬러 버퍼에 저장된다. 픽셀의 색은 보통 RGBA8888형식을 사용한다.
디스플레이 하드웨어는 프레임 버퍼의 내용을 주기적으로 읽는다.
렌더링 엔진에는 프레임 버퍼가 최소 두 개 있다. 디스플레이 하드웨어가 하나를 읽는 동안 렌더링 엔진은 다른 버퍼를 업데이트 한다.(이중 버퍼링)
렌더 타겟
프레임 버퍼 외에도 깊이 버퍼, 스텐실 버퍼를 비롯해 중간 렌더링 결과를 저장하는 다양한 버퍼들이 있다.
10.1.4.7 삼각형 래스터화와 단편
삼각형을 화면에 그릴 때 삼각형이 걸쳐 있는 픽셀들을 채우는 과정을 래스터화라고 한다.
단편은 화면의 픽셀에 대응되는 삼각형의 일부 영역이다. 렌더링 파이프라인을 거치면서 버려지는 경우도 있고, 버려지지 않는다면 프레임 버퍼에 색이 기록된다.
단편은 몇 번의 테스트(깊이, 스텐실)를 통과한 후에 프레임 버퍼에 기록된다.
단편의 색은 프레임 버퍼에 기록되거나 기존에 있는 픽셀 색과 블렌딩된다.
10.1.4.8 차폐와 깊이 버퍼
그리는 순서에 관계없이 삼각형들이 제대로 가려지게 렌더링 엔진은 깊이 버퍼를 사용한다.
깊이 버퍼는 보통 프레임 버퍼와 같은 해상도를 갖고 각 픽셀에 대해 24비트 정수의 깊이 값과 8비트 스텐실 값을 묶어 픽셀당 32비트 포맷에 저장된다.
10.2 렌더링 파이프라인
렌더링 파이프라인의 각 단계는 다른 단계들과는 무관하게 독립적으로 동작하기 때문에 병렬화에 유리하다.
파이프라인의 한 단계(계산 셰이더)에서도 병렬화를 얻을 수 있다.
파이프라인의 설계가 잘 되었다면 모든 단계가 동시에 동작하면서도 다른 단계가 끝나기를 오래 기다리고 있는 단계가 없어야 한다.
10.2.1 렌더링 파이프라인 개요
툴 단계 (오프라인)
ㄴ 기하 형상과 표면 속성을 정의한다.
자원 다듬기 단계 (오프라인)
ㄴ 기하 형상과 재질 데이터들을 가공해 엔진에서 즉시 사용할 수 있는 형태로 변환한다.
애플리케이션 단계 (CPU)
ㄴ 보여질 가능성이 있는 메시 인스턴스를 판별하고 이것들을 재질과 함께 그래픽 하드웨어에 보내 렌더링할 수 있게 한다.
기하 형상 처리 단계 (GPU)
ㄴ 정점을 변환하고 조명을 적용한 후 동차 클립 공간으로 투영한다. 부가적으로 기하 셰이더에서 삼각형들을 처리한 다음에 절두체 클리핑을 할 수도 있다.
래스터화 단계 (GPU)
ㄴ 삼각형을 쪼개고, 색을 결정하고 다양한 테스트(z-테스트, 알파 테스트, 스텐실 테스트)를 거친 후 마지막으로 프레임 버퍼에 렌더링한다.
10.2.1.1 렌더링 파이프라인이 처리하는 데이터 형식
툴과 자원 다듬기 단계 - 메시와 재질을 다룬다.
애플리케이션 단계 - 메시 인스턴스와 하부 메시 단위로 처리한다. (하부 메시는 재질 하나와 연결된다.)
기하 형상 단계 - 하부 메시들을 정점 단위로 쪼개어 처리한다. (병렬로 처리된다.) 정점으로 삼각형을 구성한다.
래스터화 단계 - 삼각형을 단편으로 분해한다.
10.2.2 툴 단계
3DS 맥스, 마야등의 3차원 모델러를 사용하여 메시를 제작한다.
스키닝 메시를 만드는 경우 각 정점을 하나 이상의 뼈대 구조 관절에 연결시키는 작업이 필요하고, 관절들이 해당 정점에 미치는 영향을 나타내는 가중치도 같이 지정해야 한다.
아티스트가 재질에 쓰일 셰이더, 텍스처, 셰이더의 옵션, 인자를 지정하는 일들이 툴 단계에서 진행된다.
ㄴ 언리얼 엔진은 그래픽 셰이더 언어를 제공하는데 그래픽 언어로 만든 셰이더들은 나중에 렌더링 엔지니어가 손으로 최적화해야 하는 경우가 많다.
10.2.3 자원 다듬기 단계
자원 다듬기 단계는 그 자체로 파이프라인이므로 ACP(Asset Conditioning Pipeline)이라고 불리기도 한다.
3차원 모델은 기하 형상(정점 버퍼, 인덱스 버퍼), 재질, 텍스처, 때로는 뼈대 등이 모여 이루어진다.
기하 형상과 재질 데이터는 DCC 프로그램에서 뽑아내서 플랫폼 중립적인 중간 형식으로 저장하는 것이 보통이다. 이 데이터를 더 가공해 여러 개의 플랫폼 특화된 형식으로 변환하는데, 그 수는 엔진이 지원하는 플랫폼의 개수에 따라 달라진다.
재질이나 셰이더의 요구 조건에 따라 ACP가 자원을 제작하는 방식이 바뀌기도 한다. 예를 들어 어떤 셰이더(환경 매핑을 위한 셰이더)는 정점 법선 외에도 탄젠트와 바이탄젠트 벡터를 필요로 하는 겨우가 있는데 ACP에서 이 같은 벡터들을 자동으로 만들게 할 수 있다.
장면 그래프를 사용하는 경우 이에 대한 계산도 ACP에서 하면 된다. 이 경우 정적 레벨 기하 형상들을 처리해 BSP 트리를 만든다.
미리 정적 조명을 계산하는 것도 포함한다. (라이트를 '굽는다'는 표현을 사용)
10.2.4 GPU의 간략한 역사
GPU의 주된 목적은 파이프라인의 처리량을 최대화하는 것이다. (거대한 규모의 병렬화)
그래픽과 관련되지 않은 목적 수행을 위한 GPU 프로그래밍은 GPGPU(General-purpose GPU)라고 한다.
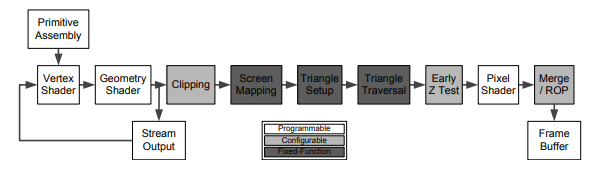
10.2.5 GPU 파이프라인
https://lemonyun.tistory.com/46
5. 렌더링 파이프라인
5.3.2 128 비트 색상 R G B A 각각 32bit씩 부동소수점 표현 가능 XMVector 형식으로 색상을 표현할 수 있고 색상 연산을 수행할 때 SIMD의 혜택을 받을 수 있음 5.3.3 32 비트 색상 XMCOLOR 구조체는 32bit 색상..
lemonyun.tistory.com
10.2.5.1 정점 셰이더(프로그래밍 가능)
모델 공간으로 들어온 정점을 뷰 공간으로 변환하는 코드를 작성할 수 있다.
10.2.5.2 지오메트리 셰이더(선택적, 프로그래밍 가능)
입력으로 기본 단위(삼각형, 선분, 점)를 culling하거나 수정하거나 새로운 기본 단위를 만들 수도 있다.
사용 예시
ㄴ 그림자 볼륨 밀어내기
ㄴ 큐브 맵의 여섯 면을 렌더링하기
ㄴ 실루엣 모서리를 따라 fur fin 밀어내기 (?)
ㄴ 파티클 효과에서 점 데이터로 쿼드 생성하기
ㄴ 동적 테셀레이션
ㄴ 번개 효과를 위한 선분 프랙탈 분할
ㄴ 옷감 시뮬레이션
10.2.5.3 스트림 출력
어떤 GPU는 파이프라인에서 지금까지 처리된 데이터를 다시 메모리에 저장하는 기능을 지원한다.
10.2.5.4 클리핑(고정, 일부는 설정)
절두체에 걸치는 삼각형의 일부를 잘라낸다. 클리핑하는 과정은 먼저 절두체 밖에 있는 정점들을 알아내고, 삼각형의 모서리가 절두체의 평면과 교차하는 지점을 찾는다. 교차하는 지점들이 새로 정점이 되고, 이들을 통해 하나 이상의 새로운 삼각형을 이룬다. (고정)
절두체 평면 외에도 별도의 클리핑 평면을 더할 수 있다. (설정)
10.2.5.5 스크린 매핑(고정)
동차 클립 공간에 있는 정점들을 스크린 공간으로 이동시킴
10.2.5.6 삼각형 셋업(고정)
삼각형을 단편으로 쪼개는 과정을 효율적으로 처리하기 위해 래스터화 하드웨어를 초기화 한다.
10.2.5.7 삼각형 순회(고정)
각 삼각형을 삼각형 순회 단계에 의해 단편들로 쪼갠다.(래스터화) 보통 픽셀 하나당 단편 하나를 만들지만 다중 샘플 안티엘리어싱(MSAA)를 하는 경우에 픽셀 하나에 여러 단편들을 만든다.
픽셀 셰이더를 위한 단편 속성을 만들기 위해 정점 속성을 보간한다.
10.2.5.8 이른 z-테스트 (하드웨어에 따라 다름)
상당수의 그래픽 카드는 파이프라인의 현 단계에서 단편의 깊이를 체크하는 기능을 지원한다. 프레임 버퍼에 있는 픽셀(이미 그려진 단편?)에 가려지는 경우 단편을 버릴수 있기 때문에 버려진 단편에 대해 픽셀 셰이더를 거치지 않게 되어 시간을 절약할 수 있다.
10.2.5.9 픽셀 셰이더 (프로그래밍 가능)
단편 단위 속성들의 모음을 입력으로 받는다.
단편의 색을 최종 결정한다.
단편을 버릴 수도 있다.
10.2.5.10 합치기 / 래스터 작업 단계 (프로그래밍할 수는 없지만 설정 가능)
깊이 테스트, 알파 테스트, 스텐실 테스트가 이 단계이다.
10.2.6 프로그래밍 가능한 셰이더
10.2.6.1 메모리 접근
GPU가 구현하는 데이터 처리 파이프라인 특성상 RAM에 접근하는 일은 세심하게 제어된다.
셰이더 프로그램은 메모리를 직접 읽거나 쓸 수 없다. 대신에 레지스터와 텍스처 맵을 통해 메모리에 접근할 수 있다.
1. 셰이더 레지스터
GPU 레지스터는 모두 128비트 SIMD 형식이다.
레지스터 하나로 32비트 자료를 4개 담은 4차원 벡터 하나를 표현할 수 있다.
행렬은 서너개의 레지스터를 묶어서 표현할 수 있다.
입력 레지스터
ㄴ 셰이더가 입력 데이터를 받는 주요한 수단
ㄴ GPU는 셰이더를 호출하기 전에 비디오 RAM에서 데이터를 입력 레지스터에 복사한다.
상수 레지스터
ㄴ 애플리케이션이 값을 지정하여 셰이더에 보낸다.
ㄴ 셰이더에서 필요로하지만 정점 속성으로 제공되지 않는 온갖 매개변수 (모델-뷰 행렬, 투영 행렬, 조명 매개변수 등)
임시 레지스터
ㄴ 셰이더 프로그램 안에서 사용할 수 있고 보통 중간 값을 저장하는데 사용한다.
출력 레지스터
ㄴ 셰이더의 출력물은 출력 레지스터에 저장된다.
ㄴ 셰이더 프로그램이 끝난 후에 GPU는 출력 레지스터 값을 다시 RAM에 저장해 다음 파이프라인 단계로 넘어갈 수 있게 한다. (보통은 캐시에 저장한다.)
2. 텍스처
ㄴ 셰이더는 텍스처를 읽기 전용 데이터로 직접 읽을 수 있다.
ㄴ 텍스처 데이터는 메모리 주소가 아닌 텍스처 좌표 (u, v)로 접근한다.
ㄴ GPU의 텍스처 샘플러가 자동으로 필터링하게 된다.(인접한 밉맵 레벨을 알아서 가져와 블렌딩한다.)
ㄴ 셰이더가 텍스처 맵에 데이터를 기록하고 싶으면 간접적인 방식을 통해야 한다. 오프스크린 프레임 버퍼에 장면을 렌더링하고 이를 다음 렌더링 패스에서 텍스처 맵으로 인식하게 하는 방식이다. (텍스처에 렌더링)
10.2.6.2 하이레벨 셰이더 언어 문법
셰이더 프로그램은 레지스터와 텍스처에만 접근할 수 있기 때문에 하이레벨 셰이더 언어에서 선언하는 struct와 변수는 셰이더 컴파일러가 레지스터에 직접 연결시킨다.
시맨틱
ㄴ 변수나 struct 멤버 뒤에 콜론을 붙이고 시맨틱이라는 키워드를 붙일 수 있다.
ㄴ 시맨틱은 셰이더 컴파일러에게 해당 변수나 데이터 멤버를 특정한 정점 혹은 단편 속성과 연결하게 알려준다.
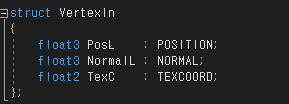
입력 값과 출력 값
ㄴ 어떤 변수나 struct가 입력 레지스터에 연결될지 출력 레지스터에 연결될지를 컴파일러가 판단할 때는 어떤 문맥으로 쓰였는지를 본다. 셰이더 프로그램의 메인 함수에 인자로 전달된 변수인 경우에는 입력 값이라고 가정하고, 리턴 값은 출력 값으로 판단한다.
uniform 선언
ㄴ 애플리케이션으로부터 상수 레지스터로 전달되는 데이터에 접근하려면 변수를 선언하면서 uniform 키워드를 사용하면 된다.
10.2.6.3 이펙트 파일
셰이더 프로그램을 엮어 완전한 시각 효과를 만들려면 이펙트 파일이라는 파일 형식을 이용해야 한다.
ㄴ 전역 공간에는 struct 값, 셰이더 프로그램들과 전역 변수들이 정의된다.
ㄴ 하나 혹은 그 이상의 테크닉을 정의한다. 테크닉은 특정한 시각 효과가 렌더링되는 한 방식을 나타낸다.
ㄴ 각 테크닉 안에 한 개 혹은 그 이상의 패스(정점, 기하, 픽셀 셰이더의 main 함수 등) 를 정의한다.
10.2.7 안티엘리어싱
10.2.7.1 전체 화면 안티엘리어싱 (Full-Screen Antialiasing, FSAA)
ㄴ 수퍼 샘플링 안티앨리어싱이라고도 불린다.
ㄴ 가로 세로 두배 큰 (4배) 프레임 버퍼에 렌더링되기 때문에 메모리 사용량이 4배가 되고 GPU 사용량도 4배가 된다.(픽셀 셰이더를 4배 더 사용)
ㄴ 프레임 렌더링이 끝나면 축소 샘플링하여 원래대로 되돌린다.
10.2.7.2 멀티 샘플링 안티엘리어싱 (MultiSampled Antialiasing, MSAA)
ㄴ 픽셀 하나에 대해 범위 테스트와 깊이 테스트는 픽셀의 슈퍼 샘플이라고 알려진 N개의 점에서 실행되지만 픽셀 셰이더는 한 번만 실행된다
10.2.8 애플리케이션 단계
1. 가시성 결정
ㄴ 보이는 물체들만 CPU에 넘겨야 한다.
2. 기하 형상을 GPU에 제출해 렌더링한다.
ㄴ 하부 메시와 재질로 이루어진 쌍을 GPU에 제출할 때는 렌더링 함수를 호출하거나 GPU 명령 리스트를 직접 조합한다.
3. 셰이더 전달 인자와 렌더 상태를 제어한다.
ㄴ 셰이더에 상수 레지스터나 버퍼로 전달되는 인자들을 설정한다.
10.2.8.1 가시성 결정
절두체 선별
https://lemonyun.tistory.com/57
16. 인스턴싱과 절두체 선별
인스턴싱 : 한 장면에서 같은 물체를 여러 번 그리는 것, 성능을 크게 향상할 수 있다. 절두체 선별 : 시야 절두체 바깥에 있는 일단의 삼각형들을 간단한 판정으로 골라내서 기각하는 기법 16.1
lemonyun.tistory.com
물체의 경계 구 와 절두체의 교차 판정(절두체의 6평면 안쪽에 있는지)을 평면 방정식을 사용하여 계산한다.
장면 그래프를 사용하면 절두체 선별 과정이 더욱 효율적이다.
차폐 선별
다른 물체에 완전히 가려지는 물체를 보이는 것들의 리스트에서 제거하는 것을 차폐 선별(occlusion culling) 이라고 한다.
잠재적 가시 그룹 (PVS, potentially visible set)
ㄴ 규모가 큰 환경에서는 미리 계산된 잠재적 가시 그룹을 통해 대략적인 차폐 선별을 할 수 있다.
ㄴ 카메라가 바라보는 공간에서 보일만할 물체를 미리 리스트로 지정해 놓는 방법
포탈
ㄴ 게임 월드의 지역을 연결하는 창문이나 문 같은 구멍을 포탈이라고 한다.
ㄴ 카메라의 초점에서 포탈의 폴리곤 모서리들로 이어지는 평면들을 만들고 이것들로 이루어지는 절두체 모양의 입체 (포탈 볼륨)을 만든다.
차폐 볼륨 (안티 포탈)
ㄴ 포탈의 개념을 뒤집으면 어떤 물체에 가려서 완전히 보이지 않는 지역을 나타내는데 피라미드형 입체를 쓸 수 있다. 물체의 경계 모서리들을 지나는 평면들로 차폐 볼륨을 만든다. 더 멀리 있는 물체와 차폐 볼륨을 검사해 물체가 차폐 볼륨 안에 완전히 들어오는 경우에 물체를 그리지 않아도 된다.
포탈이 효과적인 상황은 밀폐된 실내 환경에서 상대적으로 적은 창문이나 문을 통해 방들이 연결돼 있는 환경을 렌더링하는 상황 (포탈이 전체 카메라 절두체에서 상대적으로 작은 비율만 차지하기 때문에 포탈 바깥에 있는 많은 물체들을 선별할 수 있다.
차폐 볼륨이 효과적인 상황은 넓은 실외 환경에서 가까운 물체들이 카메라 절두체를 상당부분 가리는 상황 (차폐 볼륨이 카메라의 절두체에서 상대적으로 큰 부분을 차지하기 때문에 많은 물체들을 선별할 수 있다.)
10.2.8.2 기본 단위 제출
렌더 상태
GPU 파이프라인 내 설정 가능한 모든 인자들을 모아서 하드웨어 상태, 혹은 렌더 상태라고 한다.
ㄴ 월드 뷰 행렬
ㄴ 조명 방향 벡터
ㄴ 텍스처 연결 (재질과 셰이더에 어떤 텍스처를 쓸지)
ㄴ 텍스처 주소 지정 방식 및 필터링 모드
ㄴ 텍스처 스크롤이나 기타 애니메이션 이펙트를 위한 시간 축
ㄴ z-테스트 여부
ㄴ 알파 블렌딩 옵션
등..
상태 누수
기본 단위를 제출하기 전에 렌더 상태를 재설정해야 하는데, 이때 빠트린 것이 있다면 이전 기본 단위에 쓰였던 상태가 누수되어 다음 상태를 그리는데 영향을 준다. 재설정을 꼼꼼히 해야 한다.
10.2.8.3 기하 형상 정렬
렌더 상태 설정은 전역이다. 즉 전체 GPU에 영향을 미친다. 렌더 상태를 변경하려면 먼저 GPU의 파이프라인을 모두 비우고 새로운 설정을 적용해야 한다. 그러므로 렌더 상태를 가능한 적게 바꾸도록 해야 한다.
재질에 따라 기하 형상을 정렬하면 렌더링 성능이 저하될 수 있다. 중복 그리기(한 픽셀이 겹치는 여러 삼각형에 의해 여러번 채워지는 경우) 가 증가하기 때문이다.
이른 z-테스트는 시간이 오래 걸리는 픽셀 셰이더가 실행되기 전에 가려지는 단편들을 버리는 용도로 만든 것이다. 이른 z 테스트를 최대한 활용하려면 삼각형을 앞에서 뒤로 그려야 한다.
해결사 z-프리패스
GPU에는 픽셀 셰이더를 끄고 z-버퍼의 내용만 업데이트하는 일반 렌더링보다 몇 배 빠른 렌더링 모드가 있는데
첫 번째 렌더 단계에서 z-버퍼의 내용만 업데이트 (기하 형상들을 앞에서 뒤로 그린다.)
두 번째 렌더 단계에서 색 정보로 프레임 버퍼를 채운다.
10.2.8.4 장면 그래프
요즘에는 게임 세계가 매우 큰 경우가 많아서 게임 세계에 존재하는 모든 물체에 대해 절두체 선별을 하는 것은 시간 낭비이다. 따라서 장면 내 모든 기하 형상들을 관리하면서 자세한 절두체 선별 과정에 들어가기 전에 카메라 절두체 근처에 있지 않는 물체들을 빠르게 가려낼 자료구조가 필요하다. 이런 자료 구조를 장면 그래프라고 부른다.
쿼드 트리, 옥트리, BSP 트리, kd 트리, 공간 해시 기법이 있다.
쿼드트리와 옥트리
재귀적 방식으로 공간을 분할한다.
렌더링 엔진에서 사용하는 쿼드트리는 메시 인스턴스나 하부 지형, 정적인 메시의 개별 삼각형 등 렌더링 가능한 기본 단위들을 저장해서 효율적인 절두체 추려내기를 하는데 쓰인다. 렌더링 가능한 기본 단위는 트리의 리프에 저장되고, 각 리프마다 저장하는 기본 단위의 개수를 균등하게 만드는 것이 일반적이다.
옥트리는 쿼드트리를 3차원에 적용한 것
BSP 트리 (Binary Space Partitioning, 이진 공간 분할)
공간을 반으로 나누는데, 나누고 난 절반이 특정한 조건을 충족할 때까지 반복한다.
BSP 트리는 충돌 검출, CSG(Constructive Solid Geometry) 등 여러 곳에 쓰이는데, 가장 활용 빈도가 높은 곳은 3차원 그래픽의 절두체 선별과 기하 형상 정렬이다.
BSP 트리 개념을 k-차원으로 일반화한 것이 kd-트리이다.
10.2.8.5 장면 그래프 선택
장면을 렌더링할 때 필요한 것이 무엇인지를 분명히 이해하고 있어야 게임의 장면에 맞는 자료구조를 사용할 수 있다.
밀폐된 실내 환경을 주 배경으로 하는 게임이라면 BSP 트리나 포털 시스템이 유용하다.
평탄한 실외를 배경으로 하고 주로 위에서 내려다보는 장면이 많은 게임의 경우 (RTS) 단순한 쿼드트리만 써도 좋다.
실외 장면을 평지에서 보는 경우 별도의 선별 방식이 필요할 수도 있다. 밀도가 높은 장면의 경우 가리는 물체가 많기 때문에 차폐 볼륨 시스템을 쓰면 도움이 될 수 있다.
장면 그래프를 고를 떄 최선의 방식은 렌더링 엔진의 성능을 실제로 측정해 보고 얻은 구체적 데이터를 바탕으로 고르는 방식이다.
10.3 고급 조명 기법과 전역 조명
10.3.1 이미지 기반 조명
고급 조명 및 셰이더 기법 중에는 이미지 데이터(2차원 텍스처 맵)를 활용하는 것들이 많다.
10.3.1.1 법선 매핑
법선 맵은 각 텍셀의 표면 법선 방향을 나타내는 벡터를 담고 있다.
10.3.1.2 높이 맵: 범프, 시차, 변위 매핑
시차 차폐 매핑
ㄴ 높이 맵의 정보를 사용하여 텍스처 좌표를 조정한다.
변위 매핑
ㄴ 실제로 테셀레이션을 하여 정점을 만들고 위치를 조정한다. 실제 기하 형태로 만들어지기 때문에 자체적으로 가리기와 그림자를 생성한다.
10.3.1.3 정반사(광택) 맵
정반사 맵은 각 텍셀에 정반사도를 저장한 텍스처이다.
대다수 표면의 광택은 균등하지 않기 때문에 정교한 정반사도를 저장하고자 할 때 사용할 수 있다.
10.3.1.4 환경 매핑
환경 맵은 물체를 둘러싼 전반적인 조명 환경을 나타낸 것이다. 큰 비용을 들이지 않고도 조명 환경의 반사를 구현하는데 쓰인다.
구형 환경 맵이나 큐브 환경 맵의 형식을 주로 사용한다.
10.3.1.5 3차원 텍스처
오늘날의 그래픽 하드웨어는 3차원 텍스처를 지원한다. 3차원 좌표(u, v, w)가 주어지면 GPU가 알아서 3차원 텍스처의 주소를 찾고 필터링한다.
10.3.2 HDR 조명
프레임 버퍼의 색 채널이 0과 1사이 범위보다 큰 값을 다루기 위해 HDR 조명을 사용한다.
10.3.3 전역 조명
표면끼리 가릴 때 생기는 그림자, 반사 초곡면 효과을 표현
어떤 물체의 색이 주변 물체에 배어 나오는 현상을 표현
10.3.3.1 그림자 렌더링
가장 널리 쓰이는 그림자 렌더링 기법은 그림자 볼륨과 그림자 맵이다.
그림자 볼륨
ㄴ 그림자를 내는 광원의 위치에서 그림자를 지게하는 물체들을 바라보고 물체의 외곽선 모서리들을 구한다.
ㄴ 스텐실 버퍼를 사용하여 그림자를 렌더링한다.
https://lemonyun.tistory.com/52
11. 스텐실 적용
스텐실 버퍼는 후면 버퍼, 깊이 버퍼와 해상도가 같다. 스텐실 버퍼는 특정 픽셀 단편들이 후면 버퍼에 기록되지 못하게 하는 역할을 한다. PSO 에 D3D12_DEPTH_STENCIL_DESC 구조체를 채워 설정할 수 있
lemonyun.tistory.com
그림자 맵
그림자 맵 기법은 카메라의 시점이 아닌 광원의 시점에서 수행하는 단편 단위 깊이 테스트다.
장면을 두 단계로 나눠 렌더링한다.
첫째 단계는 광원의 시점에서 장면을 렌더링한 후 깊이 버퍼의 내용을 따로 저장해서 그림자 맵 텍스처를 만든다. 그림자 맵을 렌더링할 때는 하드웨어에 있는 초고속 z-only 모드를 이용한다.
둘째 단계는 장면을 통상적으로 렌더링하고 그림자 맵을 사용해 각 단편이 그림자 안에 들어가는지를 판별한다.
ㄴ 정점들을 광원 공간으로 변환하고, 광원 공간의 (x,y) 좌표를 그림자 맵의 텍스처 좌표 (u,v)로 변환한 뒤 광원 공간 z 좌표와 그림자 맵에 저장된 깊이 정보와 비교한다.
10.3.3.2 환경광 차폐(Ambient occlusion)
환경광 차폐는 원통형 파이프와 같이 빛이 도달하기 어려운 부분(원통의 내부)이 있는 물체의 컨택트 섀도우(contact shadow) (환경광으로 장면을 조명할 때 생기는 약한 그림자)를 모델링하는 기법이다.
정적인 물체에 대해서는 오프라인에 미리 계산할 수도 있다. 환경광 차폐는 시선 방향과 빛의 입사각과는 무관하기 때문이다.
https://lemonyun.tistory.com/62
21. 주변광 차폐
21.1 반직선 투사를 통한 주변광 차폐 3차원 모형을 주변광 항으로만 조명하면 물체 전체에 하나의 색이 고르게 입혀진 모습이 나옴 주변이 얼마나 가려졌는지를 추정하여 차폐도(가려진 정도)를
lemonyun.tistory.com
10.3.3.3 반사
1. 반짝이는 물체에 반사되는 대강의 주변 환경을 반사할 때는 환경 맵을 사용한다.
2. 거울 등의 평평한 표면에 직접 반사되는 것을 구현할 때는 카메라의 위치를 반사 표면에 대칭시키고 그 위치에서 장면을 텍스처에 렌더링한다. 그런 후 두 번째 패스에서 이 텍스처를 반사 표면에 입힌다. (스텐실 버퍼를 사용한 스텐실 판정 기법을 사용한다.)
(카메라를 대칭시키는게 아니라 메시를 반사하는 방법도 있다. DirectX 루나책 11장 평면 거울 구현할 때 이렇게 했었다.)
10.3.3.4 초곡면 효과
초곡면 효과란 물이나 광택 있는 금속 등에서 발생하는 강렬한 반사 혹은 산란으로, 매우 밝은 정반사 하이라이트다.
초곡면 효과는 어느 정도 랜덤한 하이라이트를 담고 있는 텍스처를 원하는 표면에 투영하는 식으로 구현한다.
10.3.3.5 표면하 산란
표면하 산란 - 빛이 표면의 한 점으로 들어가면 표면 아래에서 산란한 후 다른 지점에서 밖으로 나오는데, 이것을 표면하 산란(Subsurface scattering) 이라고 부른다. 사람의 피부나 밀랍, 대리석 조각상이 따스한 질감을 보이는 이유가 이 때문이다.
10.3.3.6 PRT (PreComputed Radiance Transfer)
입사광이 표면에 어떻게 작용하는지를 모든 방향에서 미리 계산하고 저장하는 방식
10.3.4 지연 렌더링
통상적인 삼각형 래스터화 기반 렌더링에서 모든 조명과 셰이딩 계산은 월드곤간, 뷰 공간 또는 탄젠트 공간의 삼각형 단편들을 가지고 한다. 이 방법은 삼각형의 정점들에 대한 여러 연산을 기껏 해놓고도 래스터화 단계에서 삼각형이 z-테스트를 통과하지 못해 버려질 수도 있기 때문에 비효율적일 수밖에 없다.
지연 렌더링에서 대부분의 조명 계산은 뷰 공간이 아니라 스크린 공간에서 수행한다. 픽셀 조명에 필요한 모든 정보는 G-버퍼라고 불리는 두꺼운 프레임 버퍼(여러 개의 프레임 버퍼)에 저장한다. 장면을 완전히 렌더링한 후 G-버퍼의 정보를 이용해 조명과 셰이딩 계산을 한다.
10.3.5 물리 기반 셰이딩
물리 기반 셰이딩 모델은 아티스트와 조명 전문가가 실세계에서 직관적이고 실세계와 같은 결과를 위해 셰이더 파라미터를 설정할 수 있게 하면서 실세계에서 빛이 이동하고 물질에 반응하는 방식을 거의 정확하게 구현한다.
10.4 시각 효과와 오버레이
시각 효과를 위해 렌더링 파이프라인 위에 여러가지 특수한 렌더링 시스템 계층을 올리는 경우가 많다.
10.4.1 파티클 효과
파티클 효과가 다른 렌더링 기하 형상들과 구분되는 주요한 특징
ㄴ 상대적으로 단순한 기하 형상들이 여러 개 모여 이루어진다.
ㄴ 기하 형상들은 항상 카메라를 향한다.(예시 : 빌보드), 쿼드의 표면 법선이 항상 카메라를 향하도록 엔진에서 따로 처리를 해야한다는 뜻이다.
ㄴ 재질이 거의 예외 없이 반투명하다. 그렇기 때문에 파티클 효과는 다른 대다수의 불투명한 물체들과는 달리 엄격한 렌더링 순서를 지켜야 하는 제약을 갖는다.
ㄴ 파티클은 보통 다양한 방식으로 애니메이션한다. 파티클의 위치, 방향, 크기(스케일), 텍스처 좌표, 셰이더 전달 인자 등은 프레임마다 달라진다. 이런 변화는 직접 만든 애니메이션 곡선으로 지정할 수도 있고, 절차적인 방식으로 정의할 수도 있다.
ㄴ 파티클은 계속해서 생겼다가 없어진다. 파티클 이미터는 월드에서 지정된 속도로 파티클들을 생성하는 논리적 단위다.
파티클은 지정된 평면에 부딪히거나 정해진 수명이 다헀을 때, 혹은 다른 조건이 충족되면 없어진다.
파티클 효과를 일반적인 삼각형 기하 형상과 셰이더를 조합해 만들 수도 있지만 이런 특징들 때문에 특수화된 파티클 효과 애니메이션 및 렌더링 시스템을 사용하는 경우가 대부분이다.
10.4.2 데칼
데칼은 기하 형상들의 표면에 씌우는 상대적으로 작은 기하 형상으로, 총탄 흔적, 발자국, 긁힌 흔적, 갈라진 흔적 등이 있다.
엔진에서 데칼을 구현할 때 가장 많이 쓰는 방법은 데칼을 사각형 영역으로 모델링한 후 화면에 일직선으로 투영하는 방식이다. (스크린 공간 -> 월드 공간)
이렇게 하면 3차원 공간에 직육면체 프리즘이 생긴다. 이 프리즘이 가장 먼저 교차하는 표면에 데칼이 입혀진다.
교차하는 기하 형상의 삼각형들을 투영된 프리즘의 네 경계 평면으로 클리핑한다. 각 정점마다 적당한 텍스처 좌표를 계산하고 클리핑한 삼각형들을 데칼 텍스처에 매핑한다. 보통 시차 매핑을 사용해 깊이감을 주고, z bias를 조정해 z fighting이 일어나지 않도록 한다.
10.4.3 환경 효과
환경 효과 전용 렌더링 시스템으로 구현한다.
10.4.3.1 하늘
단순한 방법
ㄴ 3차원 기하 형상을 렌더링하기 전에 프레임 버퍼에 하늘 텍스처를 채워 넣는다.
ㄴ 하늘 텍스처는 텍셀 대 픽셀 비율이 1:1에 가깝게 렌더링해야 하기 때문에 보통 화면의 해상도와 같거나 거의 비슷하게 만든다.
일반적인 방법
ㄴ 픽셀 셰이더의 비용이 비싸기 때문에 하늘 렌더링은 대개 나머지 장면을 모두 그리고 렌더링한다.
10.3.4.2 지형
마야 같은 도구를 써서 직접 지형을 모델링하는 방법
높이 필드 지형(높이 필드 텍스처)를 샘플링하여 지형을 모델링하는 방법
지형 제작 툴에는 높이 필드를 색칠할 수 있는 전용 도구를 두는 것이 일반적이다.
ㄴ 여러 개의 텍스처를 블렌딩하여 매핑하는 기능
ㄴ 지형의 일부분에 특수한 지형지물을 일반적인 메시로 만들어 집어넣을 수 있는 기능
10.4.3.3 물
물 시뮬레이션 기법은 계속 발전하고 있다.
물의 종류에 따라 특수한 렌더링 기법이 필요한 경우가 보통이다.
물 효과를 구현하는 데는 특수한 물 셰이더와 스크롤 텍스처뿐 아니라 밑 부분의 안개에 쓰이는 파티클 효과, 거품을 표현하는 데칼 형태의 오버레이 등 수많은 요소를 쓸 수 있다.
10.4.4 오버레이
헤드업 디스플레이와, GUI 및 메뉴 시스템과 같은 오버레이들은 보통 2차원이나 3차원 그래픽을 뷰 공간이나 스크린 공간에 직접 렌더링하는 형태로 구현한다.
10.4.4.1 정규화된 스크린 좌표
2차원 오버레이의 좌표 단위로 스크린 픽셀을 쓰는 것 보다는 다양한 화면 해상도에 적용할 수 있는 정규화된 스크린 좌표(Normalized Screen Coordinates)를 사용하는 편이 낫다.
y축은 0.0부터 1.0
x축은 4:3 화면 비율의 경우 0.0부터 4/3, 16:9에서는 0.0부터 16/9의 범위를 갖도록 하는 것이 좋다.
10.4.4.3 텍스트와 폰트
텍스트 렌더링 시스템의 핵심은 화면 내의 다양한 위치와 방향에 맞게 텍스트 문자열의 문자 글리프를 순서대로 그리는 기능이다.
여러가지 언어에 따른 문자 세트의 차이와 읽기 방향 등을 처리할 수 있어야 한다.
텍스트에 애니메이션이나 2차원 효과를 지원하는 게임 엔진도 있다.
10.4.6 풀 스크린 후처리 효과
스크린 전체의 픽셀을 픽셀 셰이더에 통과시켜 원하는 효과를 적용하게 만든다.
모션 블러
ㄴ 컨볼루션 커널을 이미지에 적용해 렌더링된 이미지를 선택적으로 흐리게 만드는 방법으로 구현한다.
DoF(Depth of Field)
ㄴ 블러 깊이 버퍼의 내용을 가지고 각 픽셀을 얼마나 흐리게 할 지 조정하는 기법이다.
비그넷 (Vignette)
ㄴ 영화에 주로 사용되는 기법으로, 화면의 모퉁이 부분에서 이미지의 명도, 혹은 채도를 감소시켜 극적인 효과를 낸다.
채색 효과 : 스크린 픽셀의 색을 마음대로 변경
ㄴ 예시로 붉은 색을 제외한 다른 모든 색을 회색으로 만드는 표현을 사용할 때
'읽은 책 > 게임 엔진 아키텍처' 카테고리의 다른 글
| 12. 충돌과 강체 역학 (0) | 2022.08.17 |
|---|---|
| 11. 애니메이션 시스템 (0) | 2022.08.13 |
| 9. 디버깅과 개발 도구 (0) | 2022.08.10 |
| 8. 휴먼 인터페이스 장치 (HID) (0) | 2022.08.09 |
| 7. 게임 루프와 리얼 타임 시뮬레이션 (0) | 2022.08.09 |




