2.1 버전 컨트롤
2.1.1 버전 컨트롤을 쓰는 이유
ㄴ 모든 엔지니어가 공유할 소스코드의 중심 저장소 역할
ㄴ 모든 소스코드의 변경 이력을 보관
ㄴ 특정 상태나 시점의 기반 소스코드에 태그를 달고 필요할 때 복원하는 기능
ㄴ 버전 브랜치 기능
git, 서브버전과 같은 버전 컨트롤 시스템을 사용할 수 있다.
2.2 마이크로소프트 비주얼 스튜디오
2.2.1 소스파일, 헤더 파일, 번역 단위
소스파일(.c .cpp) = 번역 단위 (컴파일러가 한 번에 기계어 코드로 바꾸는 단위)
컴파일러는 헤더 파일이 존재하는지 모른다. C++ 전처리기가 컴파일에 번역 단위를 보내기 전에 모든 #include 구문을 헤더 파일의 내용으로 교체하기 때문이다. 덕분에 컴파일러는 번역 단위만 다루면 된다.
2.2.2 라이브러리, 실행 파일, 동적 링크 라이브러리
컴파일로 생성된 기계어는 목적 파일(.obj)에 저장된다. 목적 파일 안의 기계어는 다음과 같은 특성이 있다.
1. 재배치 가능 - 코드가 위치할 메모리 주소가 아직 결정되지 않은 상태다.
2. 링크되지 않음 - 번역 단위 안에 들어 있지 않은 외부의 함수나 전역 데이터로의 외부 참조가 아직 확정되지 않았다.
라이브러리는 목적 파일 여러 개를 묶어 놓은 집합체들이다.
링커에 의해 실행 파일로 변환된 목적 파일들은 각 번역 단위에서 확정하지 못했던 외부 함수와 전역 데이터로의 참조를 확정하게 된다. 실행 파일 내의 기계어 코드는 여전히 재배치 가능한 상태(메모리 주소가 결정되지 않은)이다. 메모리 주소는 실행 파일이 메모리에 올라가기 직전에 결정된다.
동적 링크 라이브러리 (DLL)
ㄴ 운영체제가 따로 로드하고, C++ 실행 파일의 main() 과 비슷한 형태의 시작과 끝을 처리하는 코드가 있다.
ㄴ DLL을 사용하는 C++ 실행 파일은 DLL 안에 포함되어 있는 함수 혹은 데이터에 대한 참조는 결정되지 않은 상태로 존재한다. (부분적인 링크)
ㄴ 실행 파일을 실제로 실행할 때(메모리에 올릴 때) 운영체제가 필요한 DLL이 로드되어있지 않으면 로드하여 링크되지 않은 참조를 확정한다.
ㄴ 실행 파일을 변경하지 않으면서 필요한 DLL만 개별적으로 교체할 수 있다.
2.2.4 빌드 설정
디버그 버전 빌드는 릴리즈 버전 빌드에 비해 느리게 동작하지만 프로그래머가 개발하고 디버깅하는데 필요한 중요한 정보를 제공한다.
2.2.4.1 일반적인 빌드 설정
전처리기 설정
커맨드라인 옵션을 통해 전처리기 매크로를 정의할 수 있는데 ( -D 옵션 ) 이를 이용해 조건부 컴파일을 할 수 있다.
소스코드가 실행될 대상 플랫폼도 마찬가지로 매크로를 통해 인식할 수 있기 때문에 이를 이용해 교차 플랫폼 용 소스코드 작성이 가능하다.
컴파일러 설정
목적 파일에 디버그 정보를 포함시킬 것인지 아닐 것인지 지정하는 옵션이 있다.
인라인 함수를 확장할 것인지 아닌지를 지정할 수 있다. - 확장하게 되면 인라인 함수의 실행 속도 향상을 기대할 수 있다.
인라인 함수 확장과 같은 최적화를 하면 대개 소스 코드 실행 순서가 바뀌고 변수가 사라지거나 위치가 바뀌기도 하기 때문에 디버깅하기 어려워진다. 그래서 디버그 빌드에서는 모든 최적화를 사용하지 않는다.
링커 설정
실행 파일(.exe)를 만들 것인지 동적 라이브러리(.dll)를 만들 것인지 어떤 외부 라이브러리를 링크해서 실행 파일을 만들지, 어느 경로에서 이 라이브러리를 찾을지 등을 지정할 수 있다. 보통 디버그 빌드에서는 디버그용 라이브러리를 링크하고 릴리즈 빌드에서는 최적화된 라이브러리를 사용한다.
2.2.4.2 흔히 사용하는 빌드 설정
1. 디버그 - 모든 최적화를 끔, 인라인 함수 확장은 꺼져 있으며, 디버그 정보를 최대한 갖고 있는 매우 느린 버전
2. 릴리즈 - 디버그 빌드보다 빠르지만 디버그 정보와 assertion은 포함
3. 제품 - 가능한한 많은 최적화, 디버그 정보와 assertion 미포함
4. 툴 - 오프라인 툴과 게임 간에 공유되는 라이브러리를 활용할 때 툴에 의한 사용을 위해 공유된 코드를 조건부로 컴파일( #define TOOLS_BUILD와 같은 구문을 사용하여) 하는데 사용될 수 있다.
하이브리드 빌드
일부의 번역 단위만 디버그 모드로 빌드하고 나머지 대부분은 릴리즈 모드로 빌드하는 빌드 설정
make와 같은 텍스트 기반의 빌드 시스템은 사용하기 수월하지만 비주얼 스튜디오는 프로젝트 단위로 빌드 설정을 사용하기 때문에 쉽지 않다.
빌드 설정과 테스트 용이성
빌드 설정을 여러 개 사용할수록 테스트하기는 어려워진다. 다양한 빌드 설정들 간에 차이가 미미하다고 할지라도 한 빌드에서는 치명적인 버그가 발생할 수 있기 때문이다.
2.2.4.3 프로젝트 속성
일반 속성 페이지
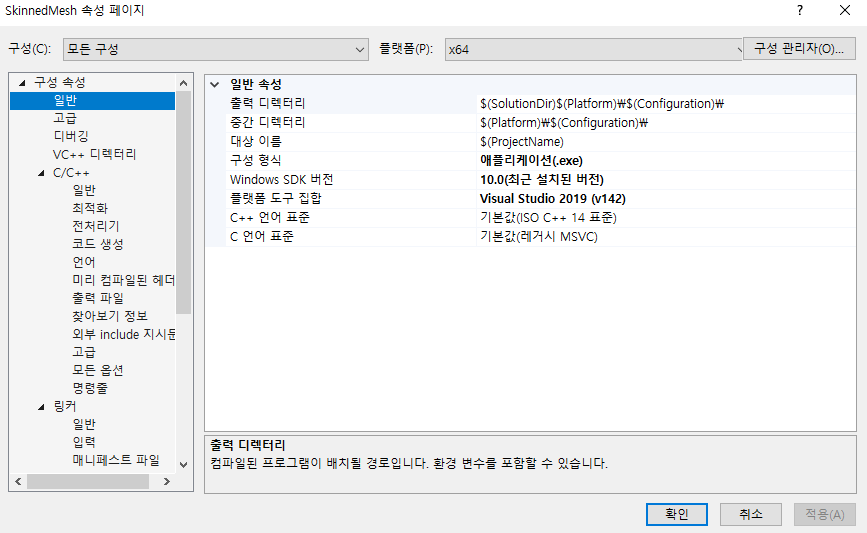
출력 디렉터리 : 실행 파일이나 라이브러리, DLL 등 컴파일러/링커가 최종적으로 만들어 낼 결과물이 어디에 저장될지를 정의한다. $(OutDir) 매크로와 동일하다.
중간 디렉터리 : 빌드 중간에 생기는 파일인 목적 파일이 어디에 저장될지 지정한다. 목적 파일은 빌드 중에만 필요하고 최종 결과물에는 포함되지 않기 때문에 최종 결과물이 저장되는 출력 디렉터리와 다르게 설정하는 게 좋다.
매크로를 사용하면 더 쉽게 설정을 바꿀 수 있다.
디버깅 속성 페이지

디버깅할 실행 파일의 이름과 위치를 지정할 수 있다.
실행될 때 전달되어야 하는 커맨드라인 명령어의 변수를 지정할 수 있다.
C/C++ 속성 페이지

소스 파일이 컴파일되어서 목적 파일이 되는 과정에 관한 컴파일-시점 언어 설정을 제어할 수 있다.
c c++ / 일반 / 추가 포함 디렉터리 : #include 된 헤더 파일을 검색할 때 로컬 디스크상의 어떤 디렉터리를 찾을지를 결정한다.
c c++ / 전처리기 : 컴파일할 때 소스 코드에 정의되어 있어야 하는 C/C++ 전처리기 심볼들의 리스트를 지정한다.
c c++ / 디버그 정보 형식 : 디버그 정보를 생성할지와 어떤 포맷으로 해야 할지를 지정한다. 보통 디버그와 릴리즈 빌드 구성은 개발 중에 문제 추적을 위해 디버그 정보를 생성하고, 최종 빌드에서는 해킹 방지를 위해 디버그 정보를 제거한다.
링커 속성 페이지

목적 파일들이 어떻게 실행 파일이나 DLL로 링크될지에 영향을 줄 속성들의 리스트를 보여준다.
링커 / 일반 / 출력 파일 : 실행 파일이나 DLL과 같은 빌드 최종 결과물의 이름과 위치들의 리스트를 보여준다. (출력 디렉터리/aaa.exe)
링커 / 일반 / 추가 라이브러리 디렉터리 : C/C++의 추가 포함 디렉터리와 비슷하게 최종 실행 파일에 링크시킬 목적 파일과 라이브러리를 찾아 볼 경로들의 리스트를 보여준다.
링커 / 입력 / 추가 종속성 : 실행 파일이나 DLL로 링크 시킬 외부 라이브러리들의 리스트를 보여준다. 새로운 라이브러리를 등록할 경우 라이브러리 디렉터리에 들어있는 라이브러리 파일명을 추가하면 된다.
비주얼 스튜디오에서는 실행 파일의 링크될 라이브러리를 정하는 구문 #pragma를 사용하면 프로젝트 속성 탭에서 라이브러리를 따로 추가하지 않고도 라이브러리를 링크할 수 있다.
DLL 파일을 사용하기 위해서는 실행파일과 동일한 폴더에 DLL 파일을 넣어야 한다.
파일을 옮기기 싫다면 디버깅 / 환경 에서 DLL이 들어있는 폴더 경로를 설정해줘야 한다.
2.2.5.8 최적화되어 있는 빌드의 디버깅에 필요한 기술
ㄴ 디버거의 디스어셈블리를 읽을 줄 아는 능력 키우기
ㄴ 레지스터를 해석해 변수 값이나 메모리 주소를 알아내기
ㄴ 주소에 의해 변수나 객체의 내용을 알아내기
ㄴ 정적 변수와 전역 변수를 활용하기
ㄴ 코드를 수정해 보기
2.3 프로파일링 툴
프로파일러는 크게 두 가지 부류로 나눌 수 있다.
1. 통계 방식 프로파일러
ㄴ CPU의 프로그램 카운터 레지스터를 주기적으로 샘플링해서 어떤 함수가 실행 중인지 알아내는 원리로 작용한다. 각 함수 안에서 수집된 샘플 숫자의 합이 전체 실행 시간에서 그 함수를 실행하는 데 걸린 시간의 근사적인 비율이다.
ㄴ 대상 프로그램에 영향을 주지 않아서 프로파일링을 적용할 때와 그렇지 않을 때의 실행 속도 차이가 별로 없다.
2. instrument 방식의 프로파일러
ㄴ 가장 폭넓은 시간 데이터 정보를 제공하지만, 실제 수행 속도 감소를 감수해야 한다.
ㄴ 프로그램의 매 함수마다 시작과 끝에 임의의 코드를 삽입하여 작동시킨다. 삽입된 코드는 프로파일링 라이브러리를 매번 호출한다.
ㄴ 콜 스택을 조사하고 어떤 부모 함수가 조사 대상 함수를 호출했는지 정보를 제공한다.
2.4 메모리 누수와 오염 감지
메모리 누수는 보통 C/C++의 포인터를 잘 못써서 발생한다.
메모리 누수 감지 프로그램을 사용할 수 있다.
ㄴ IBM PurifyPlus는 소스코드를 실행하기 전에 코드를 가공해 개발자가 실행한 모든 메몸리 비정상 참조와 메모리 할당, 해제를 감지할 수 있게 해준다.
2.5 기타 도구
ㄴ 비교 툴 : 텍스트 파일 두 개 비교하여 어떤 부분이 다른지 체크 (Diff Check)
ㄴ 합치기 툴 : 두 텍스트 파일 합치기
ㄴ 헥스 에디터
'읽은 책 > 게임 엔진 아키텍처' 카테고리의 다른 글
| 6. 리소스 시스템과 파일 시스템 (0) | 2022.08.08 |
|---|---|
| 5. 엔진 지원 시스템 (0) | 2022.08.06 |
| 4. 게임에 사용되는 3D 수학 (0) | 2022.08.04 |
| 3. 게임을 위한 소프트웨어 엔지니어링 기초 (0) | 2022.08.03 |
| 1. 소개 (0) | 2022.07.30 |



